Similarity-based Algorithms in TSMD¶
STOMP¶
The STOMP algorithm [Yeh et al. 2016] is a similarity-based method and proposes a fast computation of the Matrix Profile by efficiently leveraging the Fast Fourier Transform (FFT). Once the Matrix Profile is computed, the center of the Motif Set is defined as the subsequence with the minimum distance to another non-overlapping subsequence. A full scan of the time-series subsequences is performed, and non-overlapping subsequences that are at a distance of less than \(R\) from the center are identified as occurrences of the corresponding Motif set.
- class tsmd.competitors.matrixprofile.MatrixProfile(n_patterns: int, wlen: int, distance_name: str, distance_params={}, radius_ratio=3, n_jobs=1)¶
STOMP algorithm for motif discovery.
- Parameters
n_patterns (
int) – Number of patterns to detect.wlen (
int) – Window length.radius_ratio (
float,optional (default=3.0)) – Threshold scaling factor for pattern inclusion. (Given a Motif Pair with distance d, the threshold is equal to radius_ratio*d)distance_name (
str, optional, default"UnitEuclidean") – Name of the distance.distance_params (
dict,optional (default=dict())) – Additional distance parameters.n_jobs (
int,optional (default=1)) – Number of jobs.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
- find_patterns_()¶
Identify the most representative motifs by first running a PairMotifs search, then scanning all subsequences to determine which ones fall within a radius r of the discovered motif pairs.
- fit(signal: ndarray) None¶
Fit STOMP
- Parameters
signal (
numpy arrayofshape (n_samples,)) – The input samples (time series length).- Returns
self – Fitted estimator.
- Return type
- profile_() None¶
Compute the profile for all subsequences using parallel computation. This method divides the task into chunks based on n_jobs, and collects the neighborhood indices and distances for each subsequence.
- Returns
self – The updated MatrixProfile instance with idxs_ and dists_ attributes set.
- Return type
Usage¶
from tsmd.competitors.matrixprofile import MatrixProfile
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
mp=MatrixProfile(n_patterns=2, wlen=200, radius_ratio=3, distance_name = 'UnitEuclidean')
mp.fit(signal)
labels=transform_label(mp.prediction_mask_)
plot_signal_pattern(signal,labels)

Reference¶
[Yeh et al. 2016] Chin-Chia Michael Yeh, Yan Zhu, Liudmila Ulanova, Nurjahan Begum, YifeiDing, Hoang Anh Dau, Diego Furtado Silva, Abdullah Mueen, and Eamonn Keogh. 2016. Matrix profile I: all pairs similarity joins for time series: a unifying view that includes motifs, discords and shapelets. In 2016 IEEE 16th international conference on data mining (ICDM). Ieee, 1317–1322
PanMP¶
PanMP [Madrid et al. 2019] aims to generalize the Matrix Profile approach to detect patterns at varying time scales without requiring prior knowledge of the Motif size. To achieve this, the PanMatrixProfile—a matrix that contains Matrix Profiles for a range of window lengths in a time series—is computed. Based on distance and regardless of window size, the best non-overlapping Motif Pairs are then iteratively selected. The Motif sets are constructed from these selected Motif Pairs in the same way as in STOMP. Note that if the range of window sizes is restricted to a single value, this method functions identically to STOMP.
- class tsmd.competitors.panmatrixprofile.PanMatrixProfile(n_patterns: int, min_wlen: int, max_wlen: int, distance_name: str, distance_params={}, radius_ratio=3, normalized=False, n_jobs=1)¶
STOMP algorithm for motif discovery.
- Parameters
n_patterns (
int) – Number of patterns to detect.min_wlen (
int) – Minimium window length.max_wlen (
int) – Maximum window length.radius_ratio (
float,optional (default=3.0)) – Threshold scaling factor for pattern inclusion. (Given a Motif Pair with distance d, the threshold is equal to radius_ratio*d)distance_name (
str, optional, default"UnitEuclidean") – Name of the distance.distance_params (
dict,optional (default=dict())) – Additional distance parameters.n_jobs (
int,optional (default=1)) – Number of jobs.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
- find_patterns_()¶
Identify the most representative motifs
- fit(signal: ndarray) None¶
Fit PanMP
- Parameters
signal (
numpy arrayofshape (n_samples,)) – The input samples (time series length).- Returns
self – Fitted estimator.
- Return type
- profile_(idx: int) ndarray¶
Compute the profile for all subsequences using parallel computation for a given window length index. This method divides the task into chunks based on n_jobs, and collects the neighborhood indices and distances for each subsequence. :param idx: Index of the window length (in self.wlens_). :type idx:
int- Returns
dists (
np.ndarray) – The Matrix Profile, containing the minimal distances for each subsequence.idxs (
np.ndarray) – The Index Profile, containing the indices of the nearest neighbors.
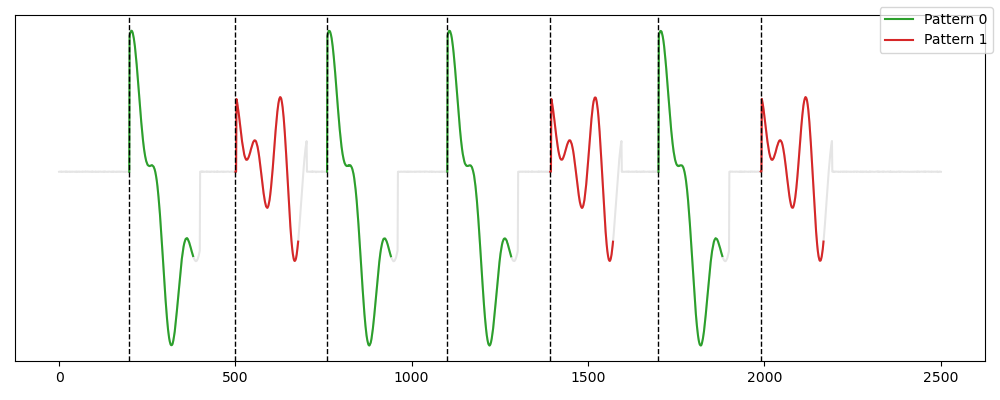
Usage¶
from tsmd.competitors.panmatrixprofile import PanMatrixProfile
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
pmp=PanMatrixProfile(n_patterns=2, min_wlen=180, max_wlen=220, radius_ratio=3, distance_name = 'UnitEuclidean')
pmp.fit(signal)
labels=transform_label(pmp.prediction_mask_)
plot_signal_pattern(signal,labels)
Reference¶
[Madrid et al. 2019] Frank Madrid, Shima Imani, Ryan Mercer, Zachary Zimmerman, Nader Shakibay, and Eamonn Keogh. 2019. Matrix profile xx: Finding and visualizing time series motifs of all lengths using the matrix profile. In 2019 IEEE International conference on big knowledge (ICBK). IEEE, 175–182
VALMOD¶
VALMOD [Linardi et al. 2018] has a similar goal to PanMP but employs a slightly different approach. It leverages pruning techniques to compute the Matrix Profile over a range of window lengths, \(\ell\). Motif Pairs are iteratively selected based on distance normalized by the square root of the window length. Motif sets are then built from these top Motif Pairs by identifying non-overlapping subsequences within a distance \(< R\) from one of the two centers.
- class tsmd.competitors.valmod.Valmod(n_patterns: int, min_wlen: int, max_wlen: int, p=20, radius_ratio=3, distance_name='UnitEuclidean', distance_params={})¶
VALMOD algorithm for variable length motif discovery.
- Parameters
n_patterns (
int) – Number of patterns to detect.min_wlen (
int) – Minimum window length.max_wlen (
int) – Maximum window length.p (
int,optional (default=20)) – Minimal number of distances computed in any cases.radius_ratio (
float,optional (default=3)) – Threshold scaling factor for pattern inclusion. (Given a Motif Pair with distance d, the threshold is equal to radius_ratio*d)distance_name (
str, optional, default"UnitEuclidean") – Name of the distance.distance_params (
dict,optional (default=dict())) – Additional distance parameters.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
- CompLB(idx: int, i: int) ndarray¶
Computes the lower bound of the distance between subsequence T[i, l+1] and all other subsequences T[j, l+1], for a given window length index.
- ComputeMatrixProfile(idx: int) tuple¶
Computes the Matrix Profile and Lower Bound information for a given window length index.
- Parameters
idx (
int) – Index of the window length to use (in self.wlens_).- Returns
MP (
np.ndarray) – The Matrix Profile, containing the minimal distances for each subsequence.IP (
np.ndarray) – The Index Profile, containing the indices of the nearest neighbors.listDP (
listofnp.ndarray) – A list of DP objects (or named tuples) for each subsequence, each containing:idx_sort (np.ndarray): Indices of the p smallest distances.
trunc_dist (np.ndarray): Corresponding distances.
trunc_LB (np.ndarray): Corresponding lower bounds.
trunc_dot_prod (np.ndarray): Corresponding dot products.
- ComputeSubMP(idx: int) tuple¶
Compute the SubMatrixProfile of window length l+1 based on the current profile of length l.
- Parameters
idx (
int) – Index of the current window length in self.wlens_.- Returns
bBestM (
Bool) – True if the SubMatrixProfile is sufficient to reconstruct the full MatrixProfile of length l+1, False otherwise (i.e., additional distances need to be computed).SubMP (
np.ndarray) – The computed SubMatrixProfile.IP (
np.ndarray) – The index profile associated with SubMP. Each entry corresponds to the index of the best match (i.e., the subsequence with the minimum distance).
- Valmod()¶
Compute the Variable length matrix profile (VALMP)
- fit(signal)¶
Fit VALMOD
- Parameters
signal (
numpy arrayofshape (n_samples,)) – The input samples (time series length).- Returns
self – Fitted estimator.
- Return type
- updateDistAndLB(idx: int, i: int, j: int, dot_product: ndarray, LB: ndarray) tuple¶
Updates the distance and lower bound between two subsequences when increasing the window length.
This method is used to incrementally compute the distance D[i,j] and the lower bound LB[i,j] for a longer window (length l+1) based on the values computed at length l. It also updates the dot product accordingly.
- Parameters
idx (
int) – Index of the current window length in self.wlens_.i (
int) – Index of the first subsequence (unknown T[i, l+1]).j (
int) – Index of the second subsequence (known T[j, l+1]).dot_product (
np.ndarray) – Dot product between subsequences at length l.LB (
np.ndarray) – Lower bound between subsequences at length l.
- Returns
new_distance (
np.ndarray) – Updated distance between T[i, l+1] and T[j, l+1].new_LB (
np.ndarray) – Updated lower bound values.new_dot_product (
np.ndarray) – Updated dot product for window length l+1.
Usage¶
from tsmd.competitors.valmod import Valmod
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
valmod=Valmod(n_patterns=2, min_wlen=180, max_wlen=220, radius_ratio=3, distance_name = 'UnitEuclidean')
valmod.fit(signal)
labels=transform_label(valmod.prediction_mask_)
plot_signal_pattern(signal,labels)

Reference¶
[Linardi et al. 2018] Michele Linardi, Yan Zhu, Themis Palpanas, and Eamonn Keogh. 2018. Matrix profile X: VALMOD-scalable discovery of variable-length motifs in data series.In Proceedings of the 2018 international conference on management of data. 1053–1066.
\(k\)-Motiflets¶
Unlike most other algorithms in our benchmark that require the user to set a radius parameter \(R\), the k-Motiflets [Schäfer et al. 2022] method aims to discover motifs without needing this parameter. Instead, the user specifies the desired number of occurrences \(k\) for the target motif. With \(k\) defined, the method identifies the set of \(k\) non-overlapping subsequences with minimal extent, where extent is the maximum pairwise distance among elements in the set.
- class tsmd.competitors.motiflets.Motiflets(k_max, min_wlen, max_wlen, elbow_deviation=1.0, slack=0.5)¶
k-Motiflets algorithm for motif discovery.
- Parameters
k_max (
int) – Maximum number of occurences of a single motif.min_wlen (
int) – Minimium window length.max_wlen (
int) – Maximum window length.elbow_deviation (
float,optional (default=1.0)) – The minimal absolute deviation needed to detect an elbow. It measures the absolute change in deviation from k to k+1. 1.05 corresponds to 5% increase in deviation.slack (
float,optional (default=0.5)) – Defines an exclusion zone around each subsequence to avoid trivial matches. Defined as percentage of m. E.g. 0.5 is equal to half the window length.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
- fit(signal)¶
Fit Motiflets
- Parameters
signal (
numpy arrayofshape (n_samples,)) – The input samples (time series length).- Returns
self – Fitted estimator.
- Return type
- fit_k_elbow(motif_length=None, exclusion=None)¶
Plots the elbow-plot for k-Motiflets.
This is the method to find and plot the characteristic k-Motiflets within range [2…k_max] for given a motif_length using elbow-plots.
Details are given within the paper Section 5.1 Learning meaningful k.
- Parameters
k_max (
int) – use [2…k_max] to compute the elbow plot (user parameter).motif_length (
int) – the length of the motif (user parameter)exclusion (
2d-array) – exclusion zone - use when searching for the TOP-2 motifletsfilter (
bool, defaultTrue) – filters overlapping motiflets from the result,plot_elbows (
bool, defaultFalse) – plots the elbow ploints into the plot
- Returns
dists: distances for each k in [2…k_max] candidates: motifset-candidates for each k elbow_points: elbow-points
- Return type
Tuple
- fit_motif_length(subsample=2)¶
Computes the AU_EF plot to extract the best motif lengths
This is the method to find and plot the characteristic motif-lengths, for k in [2…k_max], using the area AU-EF plot.
Details are given within the paper 5.2 Learning Motif Length l.
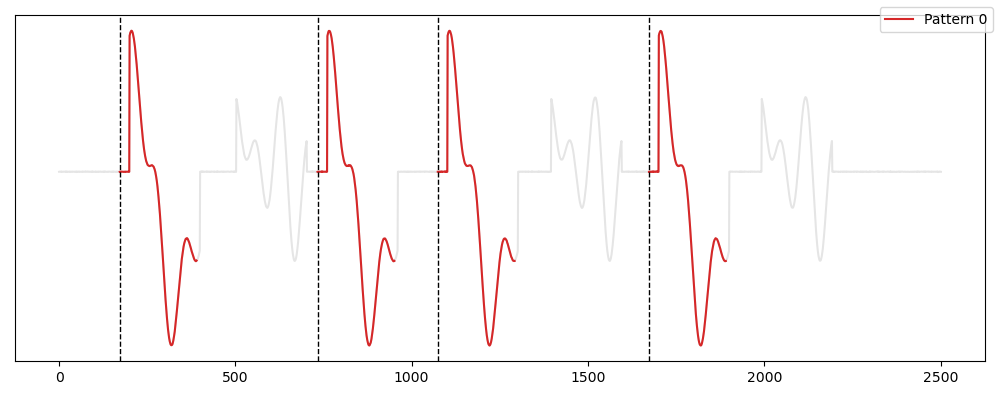
Usage¶
from tsmd.competitors.motiflets import Motiflets
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
mf=Motiflets(k_max=5, min_wlen=180, max_wlen=220)
mf.fit(signal)
labels=transform_label(mf.prediction_mask_)
plot_signal_pattern(signal,labels)
Reference¶
[Schäfer et al. 2022] Patrick Schäfer and Ulf Leser. 2022. Motiflets: Simple and Accurate Detection of Motifs in Time Series. Proceedings of the VLDB Endowment, 16, 4 (2022), 725–737.
PEPA¶
- class tsmd.competitors.persistence.BasePersistentPattern(wlen_for_persistence: int, n_patterns=None, n_neighbors=5, jump=1, distance_name_for_persistence='LTNormalizedEuclidean', alpha=10, beta=0, individual_birth_cut=False, similar_length=False, similarity=0.25, n_jobs=1)¶
PEPA algorithm for motif discovery.
- Parameters
wlen_for_persistence (
int) – Window length. A good heuristic to set the window length for PEPA is to take the average window length minus the standard deviation window length.n_patterns (
int,optional (default is None)) – Number of patterns to detect. If is None, the number of patterns is inferred.n_neighbors (
int,optional (default=5)) – Number of neighbors used to construct the graph during the first phase of PEPA.jump (
int,optional (default=1)) – Number of jumps used to compute persistance cut and birth cut.distance_name (
str, optional, default"LTNormalizedEuclidean") – Name of the distance.alpha (
float,optional (default=10.0)) – Parameter for the distance adjustement.beta (
float,optional (default=0)) – Parameter for the distance adjustement.n_jobs (
int,optional (default=1)) – Number of jobs.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
This method [Germain et al. 2024] extracts the motifs through three computational steps: (i) the time series is transformed into a graph with nodes representing subsequences and edges weighted by the distance between subsequences; (ii) persistent homology is applied to detect significant clusters of nodes, isolating them from nodes that correspond to irrelevant parts of the time series; and (iii) a post-processing step merges temporally adjacent subsequences within each cluster to form variable length motif sets. Note also that this method utilizes the LT-Normalized Euclidean distance, a distance measure invariant to linear trends.
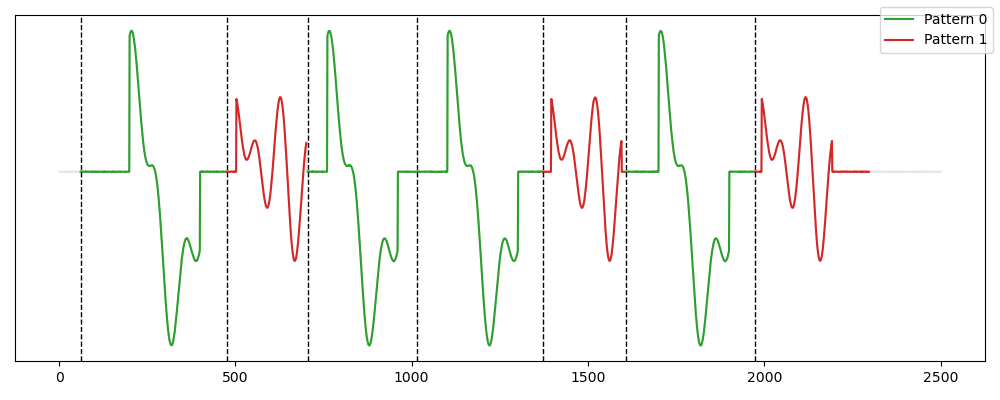
Usage¶
from tsmd.competitors.persistence import BasePersistentPattern
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
pepa=BasePersistentPattern(wlen_for_persistence=180, n_patterns=2)
pepa.fit(signal)
labels=transform_label(pepa.prediction_mask_)
plot_signal_pattern(signal,labels)
Reference¶
[Germain et al. 2024] Thibaut Germain, Charles Truong, and Laurent Oudre. 2024. Persistence-based motif discovery in time series.IEEE Transactions on Knowledge and Data Engineering (2024).
A-PEPA¶
A variant of PEPA [Germain et al. 2024] that does not require the user to define the exact number of motif sets and estimates it automatically.
- class tsmd.competitors.adaptative_persistence.AdaptativeBasePersistentPattern(wlen_for_persistence: int, n_neighbors=5, jump=2, distance_name_for_persistence='LTNormalizedEuclidean', alpha=10, beta=0, individual_bith_cut=False, similar_length=False, similarity=0.25, n_jobs=1)¶
A-PEPA algorithm for motif discovery.
- Parameters
wlen_for_persistence (
int) – Window length. A good heuristic to set the window length for PEPA is to take the average window length minus the standard deviation window length.n_neighbors (
int,optional (default=5)) – Number of neighbors used to construct the graph during the first phase of PEPA.jump (
int,optional (default=1)) – Number of jumps used to compute persistance cut and birth cut.distance_name (
str, optional, default"LTNormalizedEuclidean") – Name of the distance.alpha (
float,optional (default=10.0)) – Parameter for the distance adjustement.beta (
float,optional (default=0)) – Parameter for the distance adjustement.n_jobs (
int,optional (default=1)) – Number of jobs.
- prediction_mask_¶
Binary mask indicating the presence of motifs across the signal. Each row corresponds to one discovered motif, and each column to a time step. A value of 1 means the motif is present at that time step, and 0 means it is not.
- Type
np.ndarrayofshape (n_patterns,n_samples)
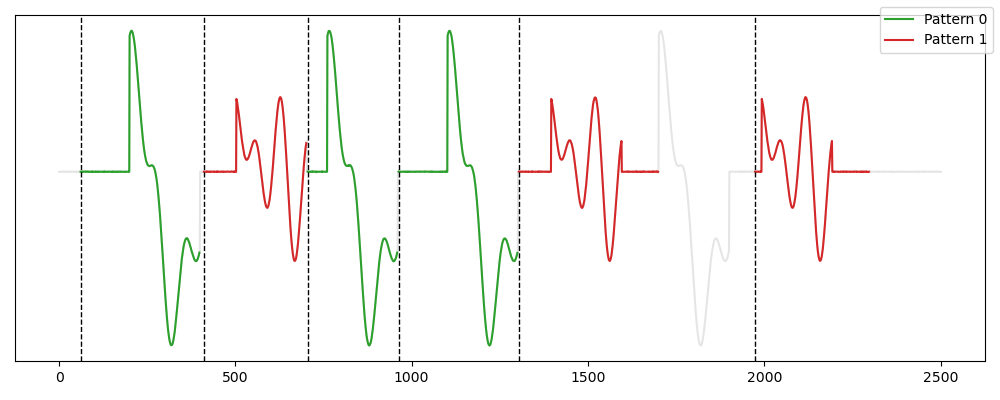
Usage¶
from tsmd.competitors.adaptative_persistence import AdaptativeBasePersistentPattern
from tsmd.tools.utils import transform_label
from tsmd.tools.plotting import plot_signal_pattern
apepa=AdaptativeBasePersistentPattern(wlen_for_persistence=180)
apepa.fit(signal)
labels=transform_label(apepa.prediction_mask_)
plot_signal_pattern(signal,labels)
Reference¶
[Germain et al. 2024] Thibaut Germain, Charles Truong, and Laurent Oudre. 2024. Persistence-based motif discovery in time series.IEEE Transactions on Knowledge and Data Engineering (2024).