Motif Discovery: A Multifaceted Problem¶
Attesting to the challenging nature of the problem, we observe several definitions of the Motif Discovery task. Indeed, if we consider the vague definition of motifs as a set of subsequences of a time series fairly close to each other, the interpretation of fairly close can lead to very different definitions of motifs. To assess the variety of definitions and, therefore, the potential ambiguity of the problem, we provide below a historical, non-exhaustive list of the main definitions in the literature.
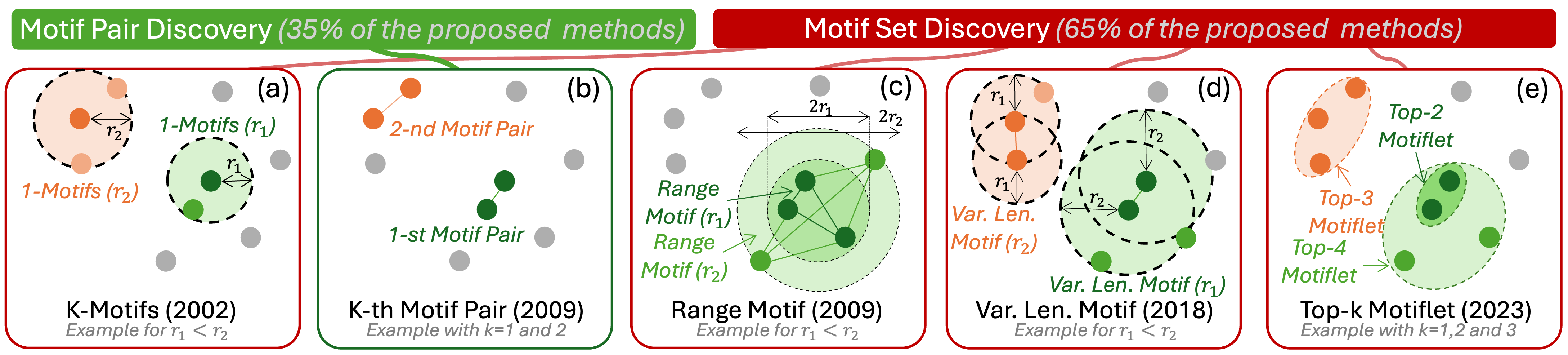
K-Motifs (2002) [Lin et al. 2002]¶
Given a time series \(S\), a subsequence length \(\ell\) and a range \(R\), the most significant motif in \(S\) (called 1-Motif) is the subsequence \(C_1\) that has the highest count of non-overlapping matches (ties are broken by choosing the motif whose matches have the lower variance). The \(k^{th}\) most significant motif in \(T\) (called K-Motif) is the subsequence \(C_k\) that has the highest count of non-overlapping matches and satisfies \(D(C_K,C_i)>2R\), for all \(1 \leq i < K\).
k-th Motif Pair [Mueen et al. 2009]¶
The Best Pair Motif of length \(\ell\) of a time series \(S \in \mathbb{R}\) is the unordered pair of time series subsequences \((S_{i,l}, S_{j,l})\) of \(S\) which is the most similar among all possible non-overlapping pairs. The kth-Pair Motif of length \(\ell\) of a time series \(S \in \mathbb{R}^n\) is the \(k^{th}\) most similar non-overlapping pair of subsequences of \(S\).
Range Motif [Mueen et al. 2009]¶
The Range Motif with range \(r\) is the maximal set of time series subsequences such that the maximum distance between them is less than \(2r\).
Variable Length Motif [Linardi et al. 2018]¶
Let \({S_{\alpha,\ell},S_{\beta,\ell} }\) be a Motif Pair of length \(\ell\) of data series \(S \in \mathbb{R}^n\) . The Motif Set \(\mathcal{M}_{r,\ell}\) is: \(\mathcal{M}_{r,\ell} = \{S_{i, \ell} ~ | ~ \text{dist} (S_{i, \ell},S_{\alpha, l}) < r \text{ or } \text{dist} (S_{i, l},S_{\beta, l}) < r \}\)
Top-k Motiflet [Schafer et al. 2022]¶
Given a time series \(S\), cardinality \(k \in \mathbb{N}\) and length \(\ell\), the top k-Motiflet of \(S\) is the set \(\mathcal{M}\) with \(|\mathcal{M}|=k\) subsequences of \(S\) of length \(\ell\) with minimal extent. Where the extent of a set \(\mathcal{M}\) is the maximal pairwise distance between subsequences of \(\mathcal{M}\).
We could complete this list with many variants of the examples above (K-Motif\((n,R,d)\), k-ball, Latent Motif, Uniform Scaling Motif). This vast list of problem definitions shows the ambiguity of Motif Discovery and the difficulty of providing a unique benchmark. However, we can distinguish between two prominent families of problems, classified according to the nature of the object returned by the methods. The first abstract problem formulation is as follows:
(Problem 1) Pair Motif Discovery:¶
Identifying the two most similar non-overlapping subsequences in a time series.
Even though Problem 1 only encapsulates K-th Motif Pair problems, it concerns approximately more than 35% of the methods proposed in the literature.
In addition, Problem 1 is well-posed, and multiple exact and approximate methods with moderate complexity exist.
However, this definition does not align with real-world applications where users seek all occurrences of the desired patterns. For example, finding only the most similar pair in electrical consumption time series is insufficient for many applications, such as unsupervised appliance detection for electrical consumption prediction.
In practice, it can be valuable for practitioners to have methods that provide a complete set of subsequences corresponding to a given motif. Toward that direction, we can state the problem as follows:
(Problem 2) Motif Set Discovery¶
Identifying sets of subsequences that encompass every occurrence of distinct repeated patterns in a time series.
While Problem 2 is deliberately more abstract than Problem 1, encompassing multiple formal definitions, it is also more general and better aligned with real-world applications of Motif Discovery. Moreover, it is important to note that the Pair Motif Discovery Problem can be seen as a sub-problem of the Motif Set Discovery Problem. Once the motif pair has been found, a Motif Set can be built around it. Several methods have been proposed in the literature to post-process the output of Pair Motif methods to solve the Motif Set problem [Bagnall et al. 2014]. For example, VALMOD [Linardi et al. 2018], which initially solves the Pair Motif Discovery problem, can then build around the identified motifs pair a set of motifs (i.e., solving the Motif Set Discovery problem).
References¶
[Lin et al. 2002] Jessica Lin, Eammon Keogh, Stefano Lonardi, and Pranav Patel. 2002. Finding motifs in time series. InProc. of the 2nd Workshop on Temporal Data Mining. 53–68.
[Mueen et al. 2009] Abdullah Mueen, Eamonn Keogh, Qiang Zhu, Sydney Cash, and Brandon Westover. 2009. Exact discovery of time series motifs. In Proceedings of the 2009 SIAM international conference on data mining. SIAM, 473–484.
[Linardi et al. 2018] Michele Linardi, Yan Zhu, Themis Palpanas, and Eamonn Keogh. 2018. Matrix profile X: VALMOD-scalable discovery of variable-length motifs in data series.In Proceedings of the 2018 international conference on management of data. 1053–1066.
[Schäfer et al. 2022] Patrick Schäfer and Ulf Leser. 2022. Motiflets: Simple and Accurate Detection of Motifs in Time Series. Proceedings of the VLDB Endowment, 16, 4 (2022), 725–737.
[Bagnall et al. 2014] Anthony Bagnall, Jon Hills, and Jason Lines. 2014. Finding motif sets in time series.arXiv preprint arXiv:1407.3685 (2014).